
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- 알고리즘
- 장고
- Optimization
- daspecialty
- programmers
- dfs
- AWS
- solution
- Medium
- twosum
- ELK
- 프로그래머스
- RecommendationSystem
- leetcode
- 리트코드
- python
- 깊이우선탐색
- Spark
- kibana
- elasticsearch
- 해시
- 엘라스틱서치
- Easy
- Algorithm
- 키바나
- Django
- CentOS
- 스파크
- 파이썬
- dump
- Today
- Total
Archive
[Snowflake] Snowflake 본문
1. Snowflake

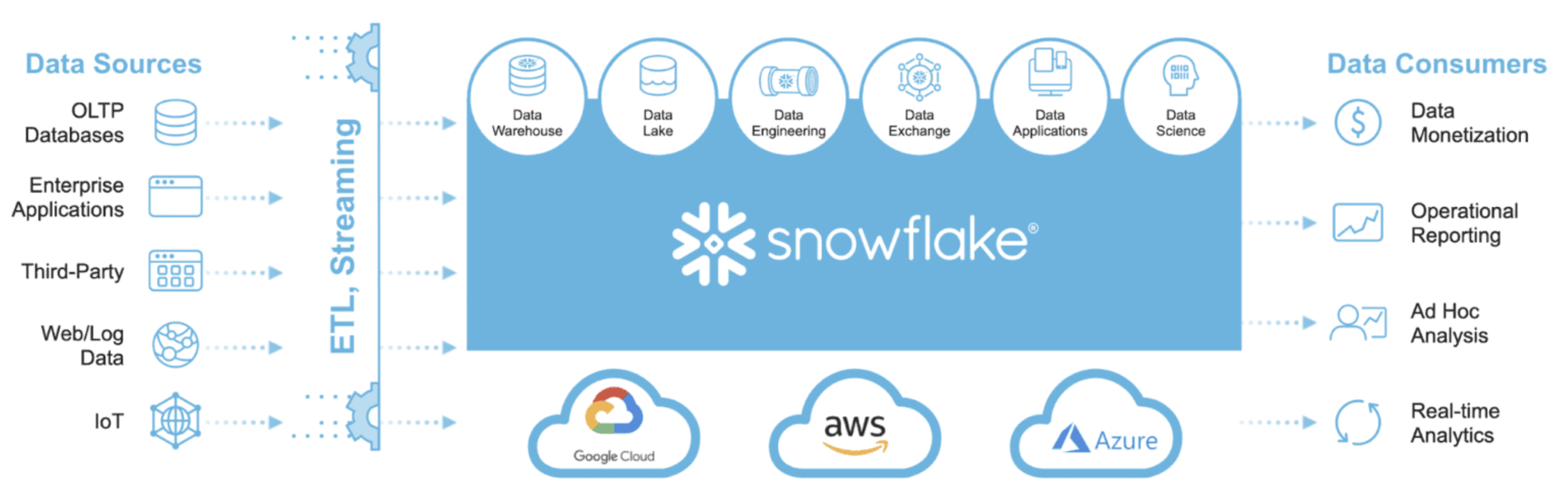
Snowflake는 SaaS 형태의 클라우드 기반의 빅데이터 솔루션으로 데이터 수집부터 처리, 저장에 이르는 모든 과정을 단일 플랫폼으로 제공한다. 즉, 기존에 On-Prem Hadoop 이나 AWS 등 단일 클라우드 에서 여러 서비스들을 조합하여 하나의 빅데이터 솔루션을 만들었다면, Data Lake 역할 및 Data Warehouse / Mart 로도 활용할 수 있는 모든 기능을 Snowflake 라는 하나의 플랫폼에 담았으며, Storage와 Computing의 분리를 통해 이 모든 Processing을 Computing 확장을 통해 각각의 workload 동시에 수행할 수 있다는 장점이 있다.
또한 Auto Scaling (Scale Up/ Scale Out ), Auto Resume/Suspend 등 운영에 필요한 다양한 기능을 제공하며 대부분의 인프라 측면을 Snowflake 에서 관리하여 기존에 운영자들이 가지던 Tuning Point도 거의 없다.
AWS / Azure / GCP 를 MSP 로서 사용 가능하며 현재 한국에선 AWS 의 Seoul 리전을 활용할 수 있다.
2. Architecture
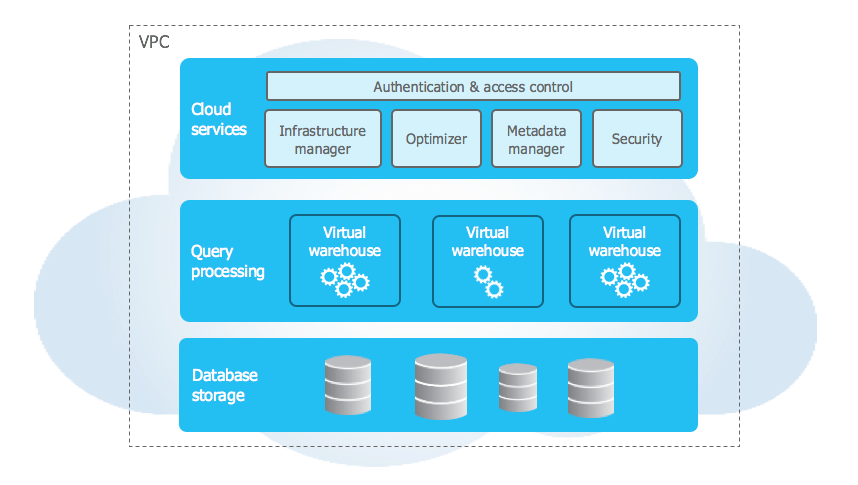
Snowflake 는 기존 Database나 Hadoop 과 같은 플랫폼 기반이 아닌 SnowSQL이라는 자체 쿼리 엔진과 Cloud용으로 설계된 아키텍처를 활용한다.
또한, 기존의 다수 서버가 Disk를 공유하는 Shared-Disk 방식과 Sharding과 같은 Shared-Nothing Database Architecture를 모두 활용하는 Hybrid Architecture이다. Shared-Disk 처럼 영구적인 데이터에 대해서는 Central Data Repository 를 사용하여 모든 Computing Node에서 접근할 수 있고, Shared-Nothing처럼 Snowflake는 Query들을 MPP(Massively Parallel Processing) Compute Cluster 를 사용하여 처리한다. MPP는 전체 Dataset의 일부를 각 Node의 Disk 에 Local 하게 저장해두어 하나의 Query를 처리할 때 여러 Process들이 개별 Node에 접근하여 데이터를 Parallel하게 처리하는 방식이다. 때문에 기본적으로 Column-Oriented로 설계되어 있고 대용량 데이터 집계에 사용된다.
이러한 Snowflake Architecture는 Shared-Disk방식에서 얻는 Data Management의 단순화와 Shared-Nothing Database 에서 오는 Performance와 Scale-Out에 대한 이점을 모두 누릴 수 있다.
1) Database Storage
Data를 Snowflake에 적재하면, Snowflake는 해당 Data를 내부 최적화 및 압축된 Column-Oriented 형식으로 재구성하고, Cloud Storage에 저장한다. Snowflake는 Data의 저장 방식과 관련된 모든 영역(Organization, File Size, Structure, Compression, Metadata, Statistics) 과 Data Storage와 관련된 영역은 Snowflake에 의해서 관리된다. 때문에 User는 Data Object를 직접 접근할 수 없고, 오로지 Snowflake 내 SQL Query 연산을 통해서만 접근할 수 있다.
2) Query Processing
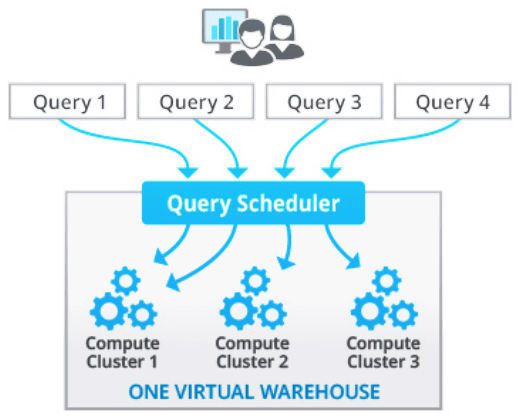
Query 는 Processing Layer에서 실행되며, Virtual Warehouse를 통해 처리된다. 각 Virtual Warehouse는 Cloud Provider (AWS/Azure/GCP) 로부터 Snowflake가 할당하는 여러 Computing Node로 구성되어있는 MPP Computing Cluster 이다. 각Virtual Warehouse는 서로 Computing Resource를 공유하지 않는 독립적인 Computing Cluster이다.
3) Cloud Service
Snowflake 전반의 작업들을 Coordinate 해주는 서비스들의 모음이다.
Authentication, Infrastructure management, Metadata management, Query parsing and optimization, Access control 을 관리하며, Cloud Provider에 Snowflake가 Provisioning하는 Computing Instance에서도 실행된다.
3. Virtual Warehouse

Virtual Warehouse는 Snowflake의 Computing Resource Cluster로, CPU, Memory, Temporary Storage와 같은 리소스를 제공한다. 내부적으로는 선택한 CSP 에서 제공하는 VM 머신 (AWS EC2 등) 을 사용한다. 쿼리를 통해 Data Load를 포함한 모든 DML 작업과 Computing 리소스를 필요로 하는 쿼리 작업 등에 활용된다.
사용자는 간단히 XS, S, M 등 T-shirt 사이즈로 warehouse를 선택해서 사용할 수 있으며, 사이즈 별로 사용 가능한 리소스 양이 다르다. 때문에 각 리소스양이 어느정도의 처리량을 가지는 지에 대해서는 테스트가 필요하다. 일반적으로 처리해야하는 데이터 양, 로드해야하는 데이터 크기 및 개수, 동시 수행해야하는 잡의 수, 처리 속도 등을 고려하여 테스트 후 비용 효율적인 Warehouse 를 선택한다. 운영 중에도 사이즈 조정 및 대수 조정하는 것이 어렵지 않으므로 너무 큰 부담은 안가져도 좋다.
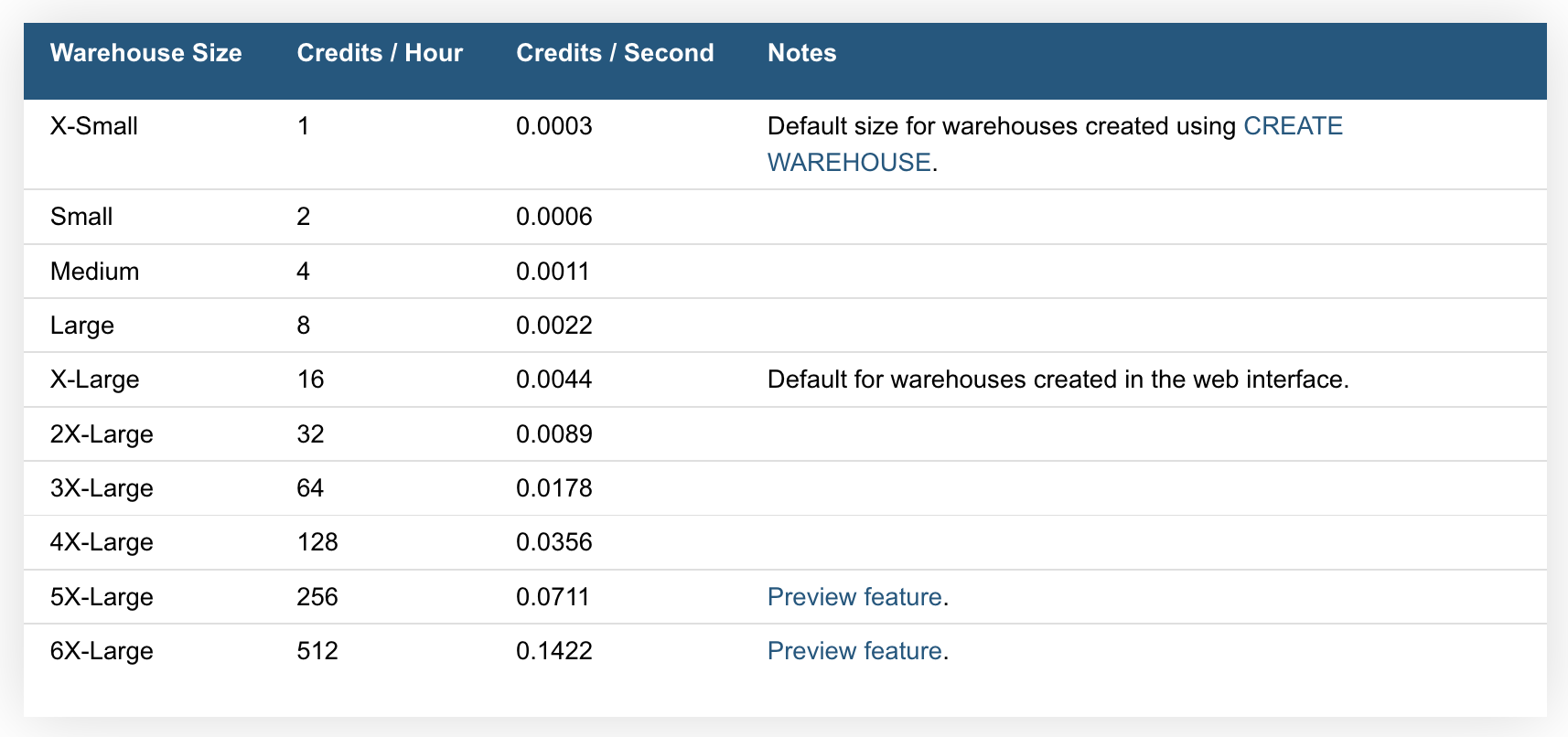
Auto-suspension and Auto-resumption
옵션을 활성화 할 경우, 일정 기간동안 사용하지 않으면 자동으로 warehouse가 중단되고, 쿼리가 실행될 때 자동으로 warehouse를 다시 시작할 수 있다. Auto scaling 과 비용 효율적 운영을 할 수 있게 된다. 다만 전체 클러스터에 대해서만 적용이 가능하고 클러스터 내 각각의 warehouse에 대해서 적용하는 것은 불가능하다.
4. Features
1) Data Sharing

Snowflake 계정끼리 Database를 공유하는 것을 말한다. 실제 데이터가 복사되거나 전송되는 것이 아니라 Snowflake 고유의 Service Layer와 Metedata Store를 통해 이루어 진다. 실제 데이터가 이동되는 것이 아니므로 공유를 받는다고 해서 Data Storage 사용량이 늘어나고, 요금이 추가되는 것이 아니다. Provider의 Database를 공유받은 Consumer는 오로지 공유받은 데이터 베이스에 날린 쿼리를 처리하는데 사용한 Virtual Warehouse 비용만 내게 된다. 또한 공유 DB로 설정된 즉시 접근할 수 있고 Snowflake의 보안 서버를 활용하여 안전하게 공유할 수 있다는 장점이 있다.
프로세스는 간단하다. Provider는 공유 DB를 생성하고 DB내의 특정 Object들에 대해 Access 권한을 Consumer에게 부여하면 Consumer쪽에는 Read-Only DB가 생성된다. Provider는 Consumer의 Access에 대한 Mornitoring을 할 수 있고, Snowflake가 제공하는 Role-based Access Control을 사용하여 Access를 관리할 수 있다.
위의 아키텍처를 통해 Snowflake는 자체 사내 조직을 포함한 여러 Consumer들과 데이터를 공유할 수 있는 Provider Network 를 생성하고, 여러 Provider의 Shared Data에 접근할 수 있는 Consumer를 생성할 수 있다.

Snowflake Marketplace는 Provider 와 Consumer를 연결해주는 서비스로, 다양한 타사의 Dataset을 검색하여 본인 Snowflake 계정으로 직접 접근하여 사용할 수 있고, 가지고 있는 Dataset과 손쉽게 결합하여 사용할 수도 있다. Provider들에게 데이터를 제공할 수 있고 Consumer들에게 쉽게 데이터에 접근할 수 있는 공간을 제공함으로써 Provider 입장에선 고객에게 제공 가능한 데이터를 listing 하여 손 쉽게 다양한 데이터를 제공할 수 있고, 데이터를 제공하기 위한 API 개발 비용 등을 줄일 수 있다. Consumer 입장에선 Data source를 통합할 수 있게되고 데이터를 받기 위한 프로세스의 개발/관리 비용을 줄일 수 있다.
2) Auto Scaling
많은 Cloud 서비스들이 Auto Scaling 을 제공하지만 Snowflake는 Scale-out 뿐만 아니라 Scale-up 도 제공하며, Auto-Suspend/Resume 기능을 활용해 더욱이 비용효율적 구성이 가능해졌다. 또한 Scale 조정이 굉장히 빠른 속도로 일어나 워크로드에 따른 빠른 대응이 가능하다. 이를 통해 인프라 관리 및 운영에 따른 리소스 절감이 가능하다.
Reference
https://docs.snowflake.com/en/user-guide/intro-key-concepts.html
https://docs.snowflake.com/en/user-guide/warehouses-overview.html
https://docs.snowflake.com/en/user-guide/data-sharing-intro.html
https://other-docs.snowflake.com/en/marketplace/intro.html
https://www.linkedin.com/pulse/snowflake-concurrency-parallel-processing-subhrajit-bandyopadhyay/
'------- DE ------- > Cloud' 카테고리의 다른 글
| [AWS][Boto3][Solution] InvalidSignatureException Error (0) | 2022.11.18 |
|---|---|
| [AWS][Athena] Pyathena를 통한 Athena 쿼리 (0) | 2022.08.05 |
| [AWS][EMR] EMR ( Master/Core/Task/AutoScaling/SpotInstance ) (0) | 2022.08.04 |
| [AWS][DX] AWS Direct Connect (0) | 2022.02.13 |


