
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 해시
- Django
- 키바나
- python
- Easy
- 장고
- 파이썬
- RecommendationSystem
- 알고리즘
- AWS
- Medium
- 엘라스틱서치
- dump
- programmers
- ELK
- twosum
- leetcode
- kibana
- 리트코드
- CentOS
- Spark
- solution
- elasticsearch
- daspecialty
- 스파크
- Optimization
- Algorithm
- dfs
- 깊이우선탐색
- 프로그래머스
- Today
- Total
Archive
[Spark] BroadCast Hash Join(BHJ) / Shuffle Sort Merge Join(SMJ) 본문
[Spark] BroadCast Hash Join(BHJ) / Shuffle Sort Merge Join(SMJ)
enent 2022. 8. 21. 00:080. Overview
Spark의 Join연산은 Executor들 사이의 방대한 데이터 이동을 일으킨다. 그것을 Shuffle이 일어난다고 표현하는데 어떤 데이터를 생성하고, 어떤 Key 관련된 데이터를 Disk에 쓰고, 어떻게 Key와 데이터들을 groupBy(), join(), sortBy(), reduceByKey() 같은 작업들을 진행하는 노드들에 옮기는지 등이 핵심이다.
Spark의 5가지의 Join 연산 방법 중 많이 쓰이는 BroadCast Hash Join, Shuffle Sort Merge Join에 대해 살펴볼 예정이다.
1. Broadcast Hash Join (BHJ)
Broadcast Hash Join (Map-Side-Only Join이라고 하기도 한다)은 Data 이동이 필요 없도록 한 쪽은 작은 Dataset, 다른 쪽은 큰 Dataset이 있을 때, Spark의 Broadcast 변수를 사용하여 더 작은 쪽의 데이터가 Driver에 의해 모든 Spark Executor에 복사되어 뿌려지고(Broadcast), 기존에 Executor 들에 남아있던 큰 Dataset과 Join (Hash Join) 하는 방식으로 이루어진다. 이렇듯 어떤 Shuffle도 일어나지 않기 때문에 Spark 가 제공하는 가장 쉽고 빠른 Join이다.

일반적으로는 Spark의 작은 쪽 Dataset이 10MB 이하일 때 Broadcast Join을 사용하게 된다. spark.sql.autoBroadcastJoinThreshold config를 통해 모든 Worker Node에 Broadcast 될 Dataset의 최대 크기를 설정할 수 있어서, 구성된 Driver / Executor의 Memory 크기에 따라 설정을 바꿔줄 수 있다. (자원이 충분하다면 100MB도 가능하다고 한다.)
만약 spark.sql.autoBroadcastJoinThreshold 가 -1 로 설정되어 있다면, Spark는 Shuffle Sort Merge Join을 먼저 수행하게 된다

When to use a broadcast hash join
- 양 쪽 Dataset의 각 Key가 Spark에서 동일한 Partition 내에 Hash 될 때
- 한 Data가 다른 한 쪽 Data보다 많이 작을 때 + 10MB (default) 혹은 충분한 Memory 가 있고, 그 안에 들어갈 수 있는 데이터 사이즈 일 때 )
- 정렬되지 않은 key를 기준으로 두 Dataset을 동등 조인할 때
- 더 작은 쪽의 Data가 모든 Spark Executor에 Broadcast 될 때 발생하는 과도한 Network 대역폭이나 OOM 에러에 대해 걱정할 필요가 없이 충분한 Resource가 있을 때
2. Shuffle Sort Merge Join (SMJ)
Shuffle Sort Merge Join은 Hash 가능한 공통의 Key를 가지면서, 공통 Partition에 존재하는 두 가지 Dataset을 활용한다. spark.sql.join.preferSortMergeJoin설정에 의해 활성화 되며 Default값은 true로, 큰 Dataset을 Join 할 때 주로 사용한다.
Shuffle Sort Merge Join은 말 그대로 데이터를 Shuffle 시켜 Sort 한 후 Join을 수행하는 것으로 Shuffle / Sort / Merge 단계로 이루어진다.
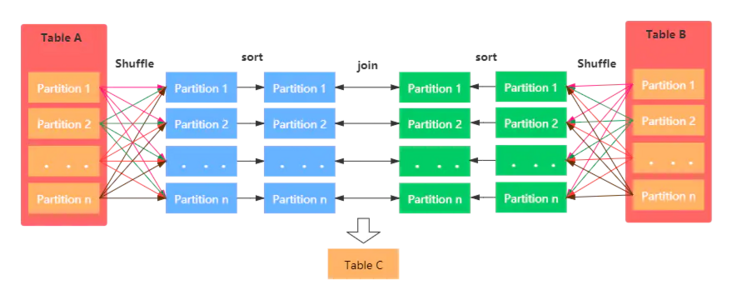
① Shuffle
두 Dataset를 읽고 Shuffle한다. Shuffle 작업 후에는 Dataset 에서 동일한 Key를 가진 Record가 동일한 Partition에 위치하게 된다.
Shuffle 과정을 생략하고 싶다면 공통의 정렬된 Key 나 Column을 위한 Partitioned 된 Bucket을 만들면 생략할 수 있다. 즉, 특정 정렬된 Column을 저장할 수 있는 Bucket을 Exchange 연산이 일어나지 않는다.
② Sort
각 데이터를 Join key에 따라 정렬한다.
③ Merge
각 Dataset에서 key 순서대로 데이터를 순회하며 Key가 일치하는 Row 끼리 Join 한다.
When to use a shuffle sort merge join
- 두개의 큰 Dataset와 각 Key가 Sorting / Hashing 되어 Spark 내에 동일한 Partition에 있을 때
- 동일한 정렬된 Key를 기반으로 두 Dataset을 결합하는 Equivalent Connection을 수행할 때
- Network 간의 Large Shuffle을 일으키는 Exchange와 Sort 연산을 피하고 싶을 때
Reference
Learning Spark(2nd) - 7. Optimizing and Tuning Spark Applications
https://www.hadoopinrealworld.com/how-does-shuffle-sort-merge-join-work-in-spark/
http://blog.madhukaraphatak.com/spark-3-introduction-part-9/
https://developpaper.com/five-join-strategies-of-spark/



