
반응형
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 |
Tags
- 파이썬
- 알고리즘
- Medium
- 리트코드
- dfs
- leetcode
- daspecialty
- 스파크
- 장고
- Spark
- elasticsearch
- Easy
- 프로그래머스
- RecommendationSystem
- CentOS
- 엘라스틱서치
- dump
- twosum
- ELK
- kibana
- programmers
- python
- solution
- Optimization
- AWS
- 키바나
- Django
- 깊이우선탐색
- Algorithm
- 해시
Archives
- Today
- Total
Archive
[Pyspark] Spark Structured Streaming v3.2.1 - 1. Programming Model 본문
------- DE -------/Spark
[Pyspark] Spark Structured Streaming v3.2.1 - 1. Programming Model
enent 2022. 5. 24. 00:55반응형
0. Overview
1. Programming Model
1.1. Basic Concepts
1.2. Handling Event-time and Late Data
1.3. Fault Tolerance Semantic
0. Overview
- Structured Streaming 는 Spark SQL 엔진을 기반으로 Streaming 처리를 위해 사용되는 라이브러리로, fast, scalable, fault-tolerant, end-to-end exactly-once stream processing 을 제공한다
- 내부적으로는 Micro-batch 형태로 처리하며, Dataset/DataFrame API를 사용하여 streaming aggregations, event-time windows, stream-to-batch joins 등의 연산 수행 가능하다
- Checkpointing and Write-Ahead Logs를 통해 end-to-end exactly-once fault-tolerance를 보장한다
1. Programming Model
- Key Idea : Live Data Stream을 지속적으로 append되는 Table로 처리한다
- Batch Processing에서 처리하는 것과 유사하게 처리할 수 있다.
- Static Table위에서 돌리는 Query 처럼, Standard Batch로 Streaming computation을 하면 Spark는 이를 Unbounded Input Table 위에서의 Incremental Query 로 실행시킨다.
1.1. Basic Concepts
- Input Data Stream 을 Input Table로 간주한다면, Stream에 도착하는 모든 새로운 데이터는 Input Table에 추가되는 새로운 Row과 같다.
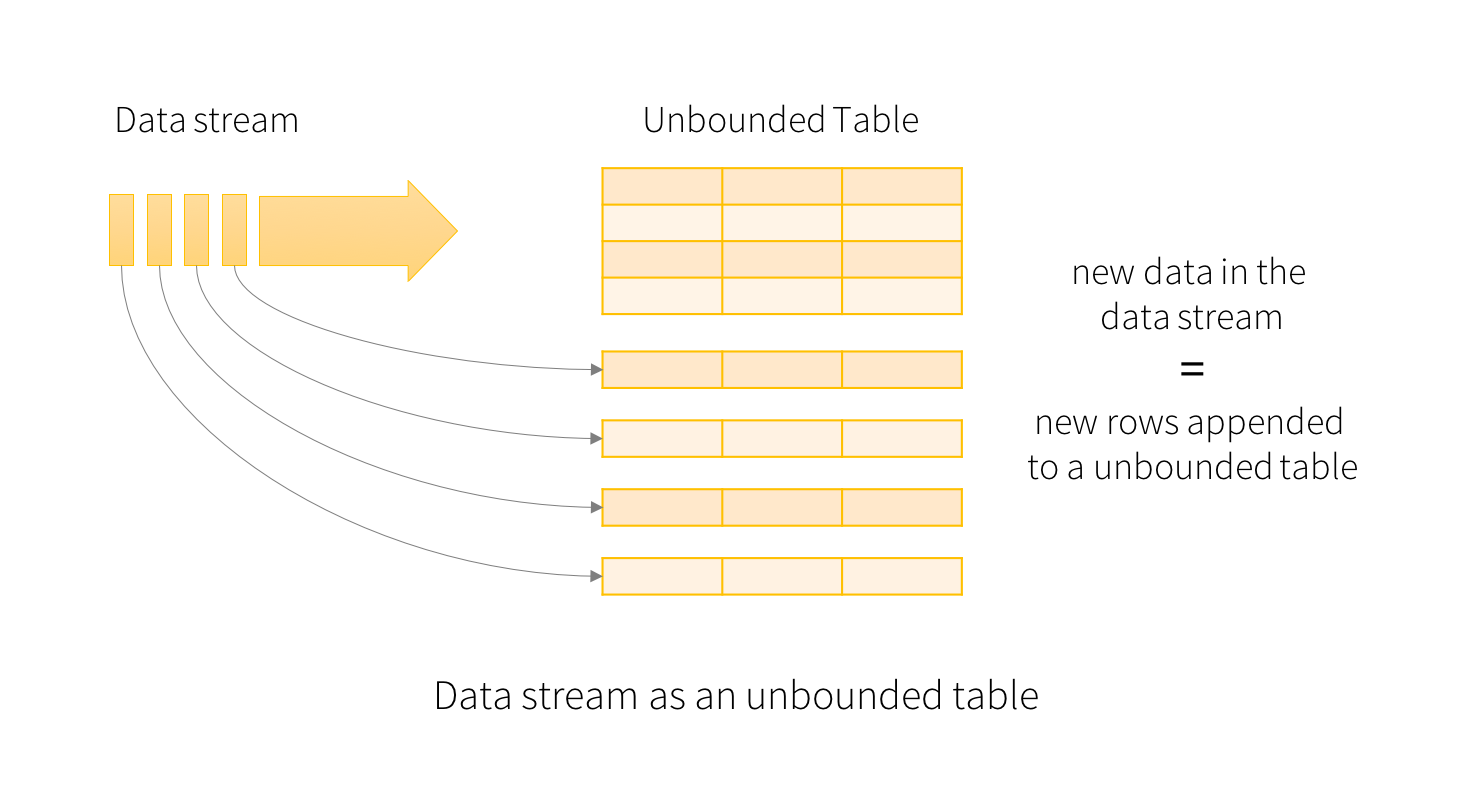
- Query에 따라서 Result Table을 생성한다.
- 모든 트리거 간격마다 새로운 Row가 Input Table에 추가 되고 결국 Result Table을 Update 한다.
- Result Table이 업데이트 되면, 변경된 결과 Row를 외부 Sink에 쓸 수 있다.
- Complete Mode - 전체 업데이트된 Result Table 을 Write (*sort 등 complete mode에서만 지원하는 함수가 있음)
- Append Mode - 마지막 트리거 이후 새롭게 Result Table에 Append 된 새로운 Row만 Write
- Update Mode - 마지막 트리거 이후 새롭게 Result Table에 Update된 새로운 Row만 Write
Ex)
from pyspark.sql import SparkSession
from pyspark.sql.functions import explode
from pyspark.sql.functions import split
spark = SparkSession \
.builder \
.appName("StructuredNetworkWordCount") \
.getOrCreate()
# Create DataFrame representing the stream of input lines from connection to localhost:9999
# Input Table
lines = spark \
.readStream \
.format("socket") \
.option("host", "localhost") \
.option("port", 9999) \
.load()
# Split the lines into words
words = lines.select(
explode(
split(lines.value, " ")
).alias("word")
)
# Generate running word count
# Output table
wordCounts = words.groupBy("word").count()
# Start running the query that prints the running counts to the console
query = wordCounts \
.writeStream \
.outputMode("complete") \
.format("console") \
.start()
query.awaitTermination()- Query 가 시작되면 Spark 는 소켓 연결하여 새로운 데이터를 지속적으로 확인하고, 새 데이터가 있는 경우 Spark 는 이전의 count와 새로운 data를 결합하여, 새롭게 Update된 횟수를 계산하는 Incremental Query 를 실행한다.

- Sturctured Streaming 은 전체 테이블을 구체화 하지 않는다.
- Source Data에서 제일 최신 데이터를 Read하고, Incrementally하게 처리하여 결과 업데이트 후 Source Data를 삭제한다.
- = Result Update를 위한 최소한의 중간 상태 데이터만 유지
1.2. Handling Event-time and Late Data
- Event = Row, Event Time = Row의 Column.
- 이를 기반으로 Window 기반의 집계 ( Ex) 분 당 이벤트 수 )를 가능하게 한다.
- 각 Time Window는 일종의 Group이고, 각 Row는 Multiple Windows/Groups에 속할 수 있다.
- Event Time을 기준으로 예상보다 늦게 도착한 데이터를 자연스럽게 처리할 수 있다.
- Spark 가 Result Table을 Update할 때, 이전 집계를 중간 상태 데이터의 사이즈를 제한하여 정리하고, 그 뿐만 아니라 늦게 들아온 데이터가 있을 때, 이전 집계를 업데이트를 Control 한다. 즉, 늦게 들어온 데이터를 이전 집계에 반영할 수 있다.
- Spark 2.1 버전 부터 늦게 들어온 데이터의 Threshold를 설정할 수 있는 Watermarking을 지원하고, 이에 따라 엔진이 이전 상태를 clean up 할 수 있다.
1.3. Fault Tolerance Semantic
Replayable Source와 Idempotent Sink를 사용하여 Structured Streming 은 End-to-End Exactly-Once Delivery를 보장한다.
- Sturctured Streaming Source, Sink, 실행 엔진을 통해 정확한 Process를 추적하여 Restarting / Reprocessing 을 통해 모든 종류의 failure를 처리할 수 있다.
- 모든 스트리밍 소스에는 위치를 추적할 수 있는 Offset이 있다고 가정하고, 실행엔진은 Checkpoint와 Write-ahead log를 이용하여 각 Trigger들에서 처리중인 데이터의 Offset 범위를 기록한다.
https://spark.apache.org/docs/latest/structured-streaming-programming-guide.html
반응형
'------- DE ------- > Spark' 카테고리의 다른 글
| [Spark] Spark Web UI (0) | 2022.08.25 |
|---|---|
| [Spark] BroadCast Hash Join(BHJ) / Shuffle Sort Merge Join(SMJ) (0) | 2022.08.21 |
| [Spark] Core of Spark SQL Engine ( Catalyst Optimizer / Tungsten ) (0) | 2022.08.19 |
| [Spark] Spark Application 에 대한 이해 ( Job / Stage / Task / Transformation / Action / Lazy Evaluation ) (0) | 2022.08.11 |
| [Spark] Spark ( Architecture / Deploy Mode / Partition ) (0) | 2022.08.09 |
'------- DE -------/Spark' Related Articles
more




Comments